【AI】如何自己训练AI大模型
人工智能领域中,尤其是大型语言模型(如GPT、BERT等),已经取得了显著的进展。对于初学者来说,自己训练一个AI大模型可能显得有些复杂,但通过循序渐进地掌握步骤,你也可以成功实现。本文将为你提供一个清晰的学习路线,帮助你更好地理解并动手操作。
1. 理解AI大模型的基础概念
首先,了解什么是AI大模型非常重要。AI大模型通常指的是具有大量参数的深度学习模型,这些模型处理的任务包括自然语言处理、图像识别等。
常见的大模型
GPT(Generative Pre-trained Transformer) :一种生成模型,专门用于文本生成。BERT(Bidirectional Encoder Representations from Transformers) :用于文本理解任务,尤其在自然语言处理(NLP)领域非常强大。T5(Text-to-Text Transfer Transformer) :一个统一的模型,可以同时处理多种类型的文本任务。学习建议 :你可以先从理解Transformer架构开始,它是大部分现代语言模型的核心架构。
2. 准备数据集
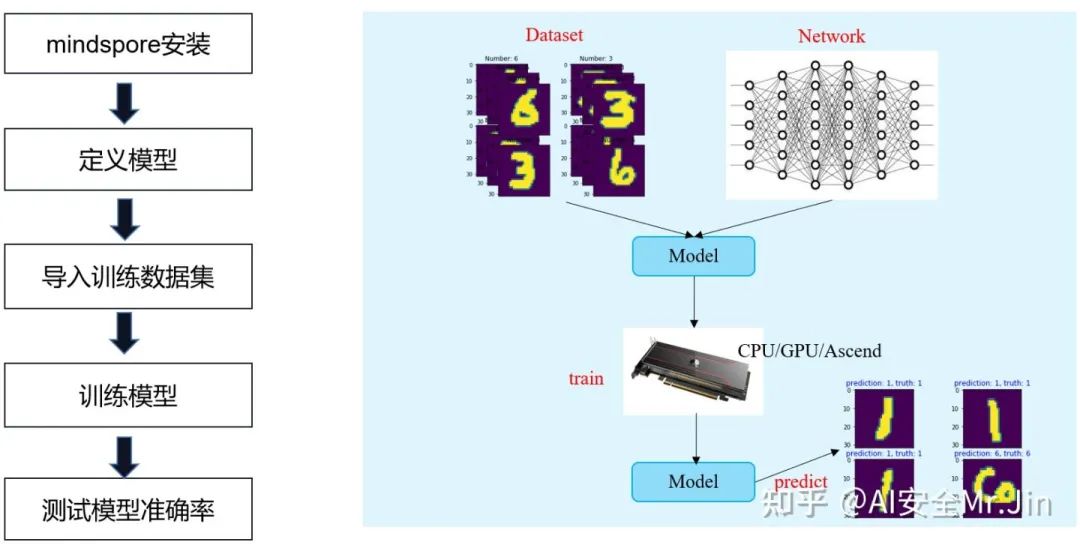
训练大模型的第一步是准备数据。没有足够且高质量的数据,模型无法有效学习和预测。
数据集选择
文本数据 :可以使用现有的公开数据集,如Wikipedia、Common Crawl等,或者根据你的任务收集定制数据。数据预处理 :数据需要经过清理、去除噪音,并进行分词等操作。数据处理技巧
文本标注 :如果你的任务需要标签(如情感分析),确保对数据进行准确标注。数据增强 :可以通过增加同义词替换、翻译等方式增强数据多样性。学习建议 :掌握Python中的数据处理库(如pandas、NumPy)以及文本处理库(如NLTK、spaCy),这些对数据预处理非常有帮助。
3. 选择合适的框架和工具
要训练AI大模型,你需要选择合适的深度学习框架。以下是一些流行且易于使用的框架:
TensorFlow :Google推出,支持大规模的训练,适合处理复杂的机器学习任务。PyTorch :Facebook推出,动态计算图非常适合调试和灵活的研究。Hugging Face Transformers :专注于NLP任务,提供了许多预训练模型,可以很方便地进行迁移学习。学习建议 :对于初学者,PyTorch的学习曲线较为平缓,且社区支持非常强大,可以考虑先从PyTorch入手。
4. 模型选择与构建
根据你的任务,选择适合的模型。大部分的AI大模型都基于Transformer 架构,专门设计来处理序列数据(如文本)。
模型选择
GPT系列 :适合文本生成任务。BERT系列 :适合文本理解任务。学习建议 :可以从Hugging Face的预训练模型库中找到适合的模型,并进行微调。这样你就可以在已有模型的基础上提高效率,而无需从头训练模型。
5. 训练模型
训练大模型需要强大的计算能力,通常需要使用GPU或TPU加速训练。
训练步骤
选择优化器 :常用的优化器如Adam、SGD,Adam通常表现较好,适用于大多数情况。选择损失函数 :根据任务选择合适的损失函数,比如分类任务常用交叉熵损失函数。调整超参数 :训练过程中,你需要调整一些超参数,如学习率、batch大小等,找到最合适的组合。训练技巧
多GPU训练 :如果你有多张GPU,可以使用分布式训练加速模型训练过程。定期保存检查点 :训练过程中定期保存模型的中间状态,这样可以在发生意外时恢复训练。学习建议 :在训练时,不要忘记进行模型评估,定期查看模型的训练曲线,避免过拟合。
6. 模型评估与优化
训练完成后,需要对模型进行评估。你可以使用验证集或测试集来衡量模型的性能。
评估方法
交叉验证 :通过将数据分成多个部分,训练多个模型,能够更好地评估模型的泛化能力。混淆矩阵 :特别适用于分类任务,能够帮助你深入了解模型在各个类别上的表现。学习建议 :学会使用各种评估指标(如准确率、F1分数)来分析模型,并根据评估结果调整模型。
7. 部署与应用
训练完成的模型需要部署到实际应用中。在这一阶段,你需要确保模型能够高效地进行推理。
部署步骤
模型压缩 :为了提高推理速度,可以进行模型压缩,如量化、剪枝等。API接口 :将训练好的模型封装为API,方便与其他系统进行交互。优化策略
TensorRT :适用于NVIDIA GPU的推理加速工具。ONNX :一个开源模型格式,可以让你在不同平台间转移模型。学习建议 :可以选择使用云服务(如AWS、Azure、Google Cloud)进行部署,这样可以避免本地硬件资源的限制。
8. 持续学习与改进
AI大模型的训练并不是一蹴而就的过程。随着新的数据和技术的出现,模型可能需要不断改进。
持续学习
迁移学习 :你可以通过微调预训练模型,在新任务上取得更好的效果。数据反馈 :根据实际使用中的反馈,更新数据集,进一步优化模型。学习建议 :多关注机器学习和深度学习领域的前沿论文,参与开源项目,和社区中的其他学习者互动。
结论
训练AI大模型是一个复杂但富有挑战的过程。通过不断地学习、实践和调整,你将能逐渐掌握模型训练的技巧。希望本文为你提供了一个清晰的学习框架,帮助你更好地理解训练大模型的每一个步骤,并成功应用于实际任务。
推荐学习资源
《Deep Learning with Python》 :适合初学者的深度学习书籍,讲解了基本概念和实践方法。Coursera的深度学习课程 :由Andrew Ng教授主讲,适合初学者。Hugging Face Transformers文档 :详细的文档帮助你快速入门。上海交大推出AI新功能,为学生“一人一案”定制科学锻炼计划

将“运动跑步”功能植入“交我办”App 上海交大 供图
用AI为学生量身打造科学的锻炼计划,“自制”跑步app记录学生跑步轨迹、配速等,在“健康中国”行动的引领下,上海交大为高校体育教育的数字化转型提供了可复制、可推广的“交大经验”。
5月24日,澎湃新闻记者从上海交大获悉,该校近日基于自主研发的DeepSeek-V3 AI大模型,推出智能锻炼建议功能,通过整合学生体育课程、体质测试、运动行为等多维度数据,为每位学生提供个性化的科学锻炼指导,有效提升了学生体育锻炼的科学性和实效性。
2021年,该校对体质测试设备进行了智能化改造,为坐位体前屈、身体成分分析仪、握力器等加装智能网联模块。学生刷校园卡或扫思源码登记身份,测试完成后数据自动后台上传,不再需要教师手工登记成绩,全程学生可自助完成体测,实现了身高体重、肺活量、坐位体前屈、握力、BMI数据的高效精准采集。2021年秋季学期,该校由此对12000余名本科学生采集体质健康指标数据400万余条,通过精准的数据分析,帮助学生准确了解体质健康水平,生成运动健康处方,指导学生科学健身锻炼。
而近期推出的AI锻炼建议功能,是上海交通大学智慧体育改革的又一重要突破。该功能基于自主研发的DeepSeek-V3 AI大模型,深度融合学生的体育课程数据、体质测试结果、场馆预约记录等多维度信息,为每位学生量身定制个性化的科学锻炼计划。无论是提升体能素质、优化运动技巧,还是合理安排锻炼时间,AI都能提供精准建议,帮助学生高效达成健身目标。
学生通过AI锻炼建议系统,能够获得系统基于最新的体质测试数据生成的全面的健康分析报告。随后,AI会根据个人身体素质、运动习惯和学习生活节奏,推荐包含有氧运动、力量训练与柔韧性训练在内的综合锻炼方案。值得一提的是,AI锻炼助手采用完全自主知识产权的DeepSeek-V3大模型,所有数据均通过校内服务器进行本地化处理,真正实现“数据不出校、隐私零风险”,为学生提供了安全可靠的数据保障。
这一功能的推出,让学生锻炼更加科学高效。AI锻炼建议功能实现了从“千人一面”到“一人一案”的个性化体育指导,为高校智慧体育建设提供了可复制、可推广的创新范例。
此外,上海交大将“运动跑步”功能植入交大学生通用的“交我办”App,把学生的日常跑步锻炼纳入体育过程性评价。基于“交我办”App自主研发“运动跑步”功能,通过日常跑步锻炼,将自主锻炼作为体育过程性评价的一部分,进一步强调课内课外相衔接,不断完善体育教育教学评价,促进“善教、乐学”,持续打造“面向人人”课内外一体化教育数字化教学体系。
App能精确分析跑步轨迹和实时配速,通过实时语音给出“跑步热身”“快一点”“慢一点”的指导提醒。通过学期跑步目标达成和班级、全校跑步榜单排名,也进一步增强了校园跑步运动社交。
澎湃新闻记者 邹佳雯
(本文来自澎湃新闻,更多原创资讯请下载“澎湃新闻”APP)
相关问答
训练ai是什么原理?
训练AI的原理是通过机器学习和深度学习等技术,让计算机系统能够自动从数据集中学习准确的模式,以取得良好的预测、分类或推理结果。基本上,训练AI的过程可以概...
ai为什么需要训练?
ai需要经过训练是因为他本来就是人创造出来的,需要被人赋予一定的行为方式,通过不断训练来熟悉这种行为方式,帮助人类做好一些工作ai需要经过训练是因为他本...
怎么训练AI?
训练AI需要经过多个步骤。首先,需要准备大量的数据集,包含输入和对应的输出。然后,使用这些数据集来训练模型。训练过程中,模型会根据输入数据逐渐调整自己的...
怎么训练智能AI?
训练智能AI是一个复杂的过程,需要多个步骤和技术。以下是一些常见的训练智能AI的方法:1.数据收集:收集大量的相关数据,这些数据将用于训练模型。2....
ai训练是什么?
在人工智能中,面对大量用户输入的数据/素材,如果要在杂乱无章的内容准确、容易地识别,输出我们期待输出的图像/语音,并不是那么容易的。因此算法就显得尤为重...
ai绘画怎么训练模型?
训练AI模型的一般过程如下:1.数据收集和准备:首先需要采集并整理与模型相关的数据,包括训练数据、验证数据和测试数据。这些数据应该具有代表性,以便模型能...
pubg新号怎么快速完成ai训练赛?
要快速完成PUBG的AI训练赛,可以采用以下几个方法:1.熟悉地图和游戏机制:在开始AI训练赛之前,最好先熟悉一下游戏地图和游戏机制,这样可以更快地找到...
AI视觉怎么训练?
AI视觉训练通常涉及收集和标注大量的图像数据,然后使用这些数据来训练深度学习模型。具体步骤包括:首先,收集与训练任务相关的图像数据集;接着,对这些图像...
人工智能训练方法?
人工智能的训练方法主要包括以下几种:1.**监督学习(SupervisedLearning)**:通过给定输入和对应的输出标签进行训练,让模型学习输入和输出之间的映射关系...
超级计算机可以训练ai吗?
超级计算机可以训练AI。例如,IBM的研究部门创建了一台名为Vela的云原生超级计算机,用于训练基础AI模型。然而,尽管超级计算机具有强大的计算能力,但它们可能...




